Chapter 6: Steps for Bivariate Analysis and Results
Basic data analyses comprise univariate, bivariate, and multivariate analyses. As we learn about univariate analysis in Chapter 5, uni-variate (one variable) analysis means examining each of the variables one by one at a time. For the Results section of the graduate research paper/thesis, the first table presents sample characteristics with outputs from univariate analyses as displayed in Table 5-1 in Chapter 5. The univariate analysis step is critical as it reviews the data as a cleaning process, and describes the sample characteristics with each of the key variables in research.
On the other hand, bi-variate (two variables) analysis means examining two variables at a time. Bivariate analysis is a part of inferential statistics, which examines the association between two variables, in particular, whether the two variables are statistically related and can infer the relationship between the two variables based on probability theory[1]. Based on bivariate analysis, we can test our study hypotheses developed for the research and presented in Literature Review such as whether the study independent variable (IV) is statistically significantly related to the study dependent variable (DV) in our research with data that we examined.
There is a distinct difference between descriptive and inferential statistics, in other words between univariate and bivariate/multivariate analyses. The scope of univariate analysis is called descriptive statistics and is limited to describing the sample characteristics of a sample. However, bivariate and multivariate analyses are called inferential statistics and aim to make predictions about population beyond the sample and can test hypotheses. Testing hypotheses is the inferential procedure to predict the relationship between IVs and DV from the sample to the population based on statistical tests by calculating the probability that can infer the findings to the population, which determines the significance of the relationship between variables. The significance level which is denoted as Alpha (α) is the probability of rejecting or accepting the study hypotheses. The significance level is usually set either at α = 0.05 (5%) or α = 0.1 (10%). α= 0.05 means that there is a 5% chance of making a conclusion that a relationship exists when there is no actual relationship.
As presented in Table 6-1, there are four major bivariate analyses: 1) Correlation, 2) Independent Sample t-test, 3) Analysis of Variance (ANOVA), and 4) Chi-square test. The first step is to determine which bivariate analytical tool we need to adopt to test the study hypothesis. This decision is based on a combination of the level of measurement of the two variables: 1) Two variables (both IV and DV) are scale measures (interval or ratio), 2) One variable (mainly IV, but can be DV) is nominal/ordinal and the other is scale (mainly DV, but can be IV), and 3) Two variables (both IV and DV) are either nominal or ordinal, definitely not scale measures.
As Table 6-1 presents, the first combination is for Correlation analysis and the third is for Chi-square (χ2) test. The second combination is for Independent Sample t-test and Analysis of Variance (ANOVA). When the IV is a nominal/ordinal measure with only two groups such as gender with females and males or any variables with Yes and No answer categories, we perform an Independent Sample t-test. When the IV is a nominal/ordinal measure with three or more groups such as race/ethnicity, marital status, and occupation with multiple occupational groups, we choose an Analysis of Variance (ANOVA) test. We review four bivariate analyses one by one.
Table 6-1. Bivariate Analysis with Level of Measurement | ||
Bivariate Analysis | Level of Measurement of the Variables | Purpose of the Test |
Pearson’s r correlation | DV scale (interval/ratio) IV scale (interval/ratio) | To test whether two variables are correlated (e.g., seniority by income) |
Chi-square test, χ2 | DV (nominal or ordinal) IV (nominal or ordinal) | To test whether there is an association between the two variables (e.g., gender by dating violence with Yes/No) |
Independent sample t –Test | DV scale (interval/ratio) IV nominal (dichotomous with two groups) | To test whether the average of one group and the average of the other group are different (e.g., income by gender on whether females’ average income and males’ average income are different). |
Analysis of Variance (ANOVA) | DV scale (interval/ratio) IV (nominal with 3 or more groups | To test whether the average of scale measures differ across three or more groups (e.g., income by race). |
Correlation Analysis
There are different types of Correlation analysis. The most frequently used correlation analysis is Pearson’s r Correlation, in which the two variables (both IV and DV) are scale measures. Correlation analysis is used to determine whether a relationship between two scale variables is statistically significant or not. The steps for Pearson’s r Correlation in SPSS are presented in Table 6-2 and Figure 6-1.
Table 6-2. Steps for Pearson’s r Correlation |
1. Go to ‘Analyze’ on the top menu in Data View or in Variable View 2. Click ‘Correlate’ 3. Click ‘Bivariate’ (the first choice) 4. Choose two variables from the variable list in the left side 5. Click the arrow to move two or multiple variables to the right side of ‘Variables’ 6. Choose ‘Pearson’ under “Correlation Coefficient” 7. Choose ‘Two-tailed’ under “Test of Significant” at the bottom 8. Click ‘Continue’ 9. Click ‘OK’ |

Figure 6-1. Steps for Pearson’s r Correlation

Figure 6-2. Output from Pearson’s r Correlation Analysis
Once a Pearson r Correlation analysis is conducted, the SPSS output window displays the results as shown in Figure 6-2. The Correlation table is a matrix with two variables in the columns and rows generating four cells. Each cell contains three pieces of information of “Pearson Correlation” in the first line, “Sig. (2-tailed)” in the second line, and “N” in the third line. These pieces of information repeat the next row of another variable. The value of “Pearson Correlation” is the correlation coefficient indicating a relationship between two variables, “Sig. (2-tailed)” is the probability value of the statistical significance of the relationship between the two variables, “N” is the number of cases included in this analysis. Each cell displays three pieces of information. The first cell in the White part displays the correlation between age and age, which is the correlation between the same variable. Thus, the correlation value is “1,” which means the two variables are identical and show perfect correlation. This is the same in the right cell at the second row because it is the correlation between the same variable of suicidal ideation and the correlation value is “1.”
In this output presented in Figure 6-2, the key concern is the correlation between age and suicidal ideation. The cells of the right on the first row and the left on the second row present the same information because the correlation between age and suicidal ideation is the same as the correlation between suicidal ideation and age regardless of the order of the variables. In this output, the Pearson correlation coefficient is -.012 and we present r = -.012 as a lowercase “r” is a statistical symbol of the Pearson correlation coefficient. This correlation coefficient is not statistically significant with a p-value of .677[2] at the level of p = 0.05.
In Correlation analysis, the correlation coefficient “r” provides two pieces of information: The direction of the relationship and the Strength of the relationship. The coefficient value is close to “1” (either +1 or -1), indicating a strong correlation between the two variables while the values close to “0” indicate little or no correlation[3]. The coefficient can be a negative value, which implies two variables have a negative relationship[4] while a positive value indicates a positive relationship. Based on outputs in Figure 6-2, a sample write-up for the Results is shown in Table 6-3. For the Results section in the graduate research paper, the output can be presented in the form of Table 6-4.
Table 6-3. Sample Write-up for Pearson’s r Correlation |
A case of an insignificant correlation: A Pearson correlation was conducted to examine whether there is a relationship between age and suicidal ideation. Results showed that there is no significant relationship between age and suicidal ideation (r = -0.012, p = 0.68). A case of a significant correlation: A Pearson correlation was conducted to examine whether there is a relationship between dating violence and suicidal ideation. Results showed that there is a statistically significant relationship between dating violence and suicidal ideation (r = .25, p = 0.01). The results indicate that dating violence increases suicidal ideation (or dating violence is positively related to suicidal ideation). |
Table 6-4. Table Template of Correlation Analysis Results | |||
Table #[5] Correlation Between Age (IV), Dating Violence (IV), and Suicidal Ideation (DV) | |||
Variable | N | r | p |
Age (* Suicidal Ideation)[6] | 1310 | -.012 | .67 |
Dating Violence (*Suicidal Ideation) | 1300 | .25 | .01 |
Independent Sample t-Test
We conduct an independent sample t-test when the independent variable is a binary nominal variable (two groups of respondents like male/female, yes/no, or experiment/control groups), and the dependent variable is a scale measure (interval or ratio levels). We can also use this test when the IV is a scale measure, and DV is a binary nominal measure. This test is used to compare the means of the scale variable for two groups of the nominal variable. For example, we can compare females’ average income to males’ average income as income is a scale measure while gender is generally made up of two groups of people (females and males). We can also compare the average suicidal ideation level of youth who experienced physical dating violence to the average suicidal ideation level of youth who did not in case suicidal ideation is collected as a scale measure and physical dating violence experience is measured as Yes or No. When we compare the outcomes between experimental and control groups, an Independent Sample t-test can be used.
Steps to conduct Independent Sample t-test displays in Figure 6-3 and Table 6-5.

Figure 6-3 Steps for Independent t-Test
Table 6-5. Steps for Independent Sample t-Test |
1. Go to ‘Analyze’ on the top menu in Data View or in Variable View 2. Choose ‘Compare Means’ on the fifth option from the top 3. Choose ‘Independent Sample T Test’ in the middle 4. Choose a scale variable from the variable list on the left side 5. Click the arrow or double click the variable to move the scale variable to the right side of ‘Test Variable(s)’ on the top right → can choose multiple scale variables 6. Choose a nominal variable and move to “Grouping Variable” 7. Click “Define Groups” under the “Grouping Variable” to tell SPSS the values of the two groups we compare 8. Put the values of two groups on the pop-up box for Group 1 and Group 2 9. Click “Continue” 10. Click ‘OK’ |
Once we conduct the Independent Sample t-test, the SPSS produces Outputs as displayed in Figure 6-4. The Outputs presented in Figure 6-4 are an Independent Sample t-test with gender and suicidal ideation. In Figure 6-4, the first table “Group Statistics” presents the mean scores of two groups of females and males with standard deviation and the number of cases included in the test (N). We compare the mean scores of suicidal ideation between females and males. In this example, the mean score of females is 0.95 while the mean score of males is 0.50, which shows that females’ suicidal ideation is higher than males. However, we are not sure whether this difference is statistically meaningful. The second table “Independent Sample Test” presents the statistical significance. The statistical significance can be checked with “Sig. (2-tailed) with t and df values on the first line. This example of gender differences in suicidal ideation is statistically significant since the p-value is smaller than 0.05 (Sig. (2-tailed) = .000).
Based on the outputs of Figure 6-4, we can report the test results as follows. Tables 6-6 and 6-7 also show how to present the Independent Sample t-test results in the table format in the Results section.
Table 6-6. Write-up Samples for Independent Sample t-Test Results |
An independent samples t-test was conducted to determine whether there is a difference in mean scores of suicidal ideation (scale variable) between two groups of gender (nominal variable). The mean score of suicidal ideation for females is 0.95 (sd = 1.09) and that for males is 0.50 (sd = 0.88). Results showed that there was a statistically significant difference in suicidal ideation between males and females (t= -8.135, df= 1302, p < .000). Females’ suicidal ideation was higher than males. |
Group Statistics | |||||
sex: male = 0 female =1 | N | Mean | Std. Deviation | Std. Error Mean | |
suicidal ideation with 25 26 27 | male | 643 | .5039 | .88139 | .03476 |
female | 661 | .9516 | 1.09160 | .04246 | |
Independent Samples Test | |||||||||||
Levene's Test for Equality of Variances | t-test for Equality of Means | ||||||||||
F | Sig. | t | df | Sig. (2-tailed) | Mean Difference | Std. Error Difference | 95% Confidence Interval of the Difference | ||||
Lower | Upper | ||||||||||
suicidal ideation with 25 26 27 | Equal variances assumed | 32.720 | .000 | -8.135 | 1302 | .000 | -.44770 | .05503 | -.55566 | -.33974 | |
Equal variances not assumed | -8.159 | 1259.517 | .000 | -.44770 | .05487 | -.55535 | -.34005 | ||||
Figure 6-4 SPSS Outputs of Independent t-Test
Table 6-7. Table Template Reporting Independent Sample t-Test Results | |||||||
Table # Suicidal Ideation by Gender (Independent Samples t-test) | |||||||
N | Mean | SD | t | df | p | ||
Gender Male Female | 643 661 | 0.50 0.95 | 0.88 1.09 | -8.14 | 1302 | 0.00 | |
One Way Analysis of Variance (ANOVA)
The purpose of One-way ANOVA is the same as Independent Samples t-test as it compares the mean scores of scale variables among 3 or more groups (nominal variable). Thus, one variable is a scale measure (interval/ratio level) (usually the Dependent Variable) and the other variable is a nominal measure with three or more groups (usually the Independent Variable). Theoretically, we assume equal variances of the groups, not mean scores to conduct ANOVA. When the variances among groups are not equal, then we conduct non-parametric tests which means the variables aren’t scale measures. This can be checked with the ANOVA test. Figure 6-5 and Table 6-8 display steps to conduct One-way ANOVA. Figure 6-6 presents SPSS output.
Table 6-8. Steps for One-Way Analysis of Variance |
1. ‘Analyze’ on the top menu in Data View or in Variable View 2. Choose ‘Compare Means’ on the fifth option from the top 3. Choose ‘One-way ANOVA’ on the last option 4. Choose a scale variable from the variable list on the left side 5. Click the arrow or double click the variable to move the scale variable to the right side of ‘Dependent List’ on the top right → can choose multiple scale variables 6. Choose a nominal variable and move to “Factor” on the bottom left 7. Choose “Post Hoc” on the second top right button 8. Choose “Sheffe” from the list on the left, the fourth choice 9. Click “Continue” 10. Choose “Options” and “Descriptive” and “Homogeneity of variance test” 11. Click “Continue” 12. Click ‘OK’ |
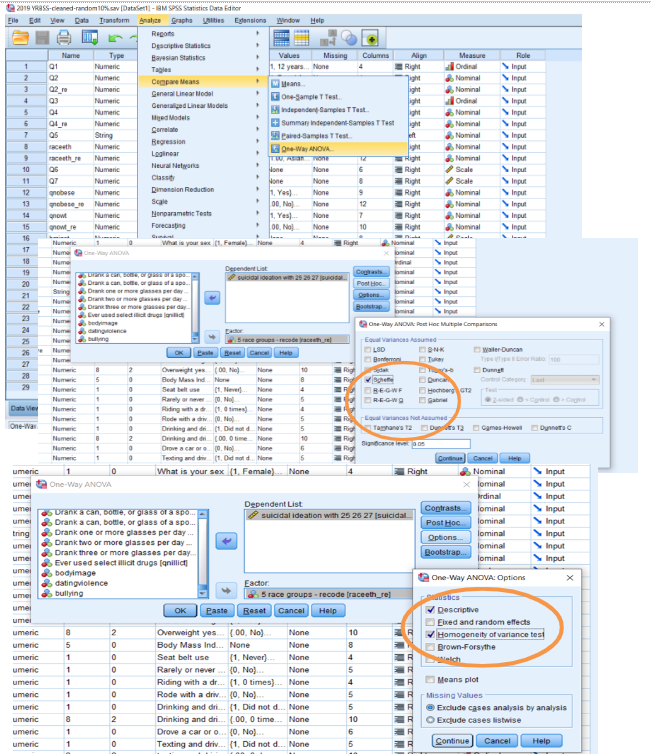
Figure 6-5. Steps for One-way Analysis of Variance
Descriptives | ||||||||
school support -listen | ||||||||
N | Mean | Std. Deviation | Std. Error | 95% Confidence Interval for Mean | Minimum | Maximum | ||
Lower Bound | Upper Bound | |||||||
latino | 844 | 3.2737 | .83643 | .02879 | 3.2172 | 3.3302 | 1.00 | 4.00 |
asian | 262 | 3.4847 | .72566 | .04483 | 3.3965 | 3.5730 | 1.00 | 4.00 |
black | 100 | 3.3500 | .75712 | .07571 | 3.1998 | 3.5002 | 1.00 | 4.00 |
white | 1127 | 3.5661 | .65753 | .01959 | 3.5277 | 3.6045 | 1.00 | 4.00 |
other | 426 | 3.4437 | .71150 | .03447 | 3.3759 | 3.5114 | 1.00 | 4.00 |
Total | 2759 | 3.4422 | .74446 | .01417 | 3.4144 | 3.4700 | 1.00 | 4.00 |
Test of Homogeneity of Variances | |||||||||
school support -listen | |||||||||
Levene Statistic | df1 | df2 | Sig. | ||||||
17.839 | 4 | 2754 | .000 | ||||||
ANOVA | |||||||||
school support -listen | |||||||||
Sum of Squares | df | Mean Square | F | Sig. | |||||
Between Groups | 42.591 | 4 | 10.648 | 19.734 | .000 | ||||
Within Groups | 1485.938 | 2754 | .540 | ||||||
Total | 1528.529 | 2758 | |||||||
Post Hoc Tests
Multiple Comparisons | ||||||
Dependent Variable: school support -listen | ||||||
Scheffe | ||||||
(I) race | (J) race | Mean Difference (I-J) | Std. Error | Sig. | 95% Confidence Interval | |
Lower Bound | Upper Bound | |||||
latino | asian | -.21104* | .05195 | .002 | -.3712 | -.0509 |
black | -.07630 | .07768 | .915 | -.3158 | .1631 | |
white | -.29241* | .03344 | .000 | -.3955 | -.1893 | |
other | -.16997* | .04366 | .004 | -.3045 | -.0354 | |
asian | latino | .21104* | .05195 | .002 | .0509 | .3712 |
black | .13473 | .08634 | .656 | -.1314 | .4009 | |
white | -.08137 | .05038 | .625 | -.2367 | .0739 | |
other | .04107 | .05767 | .973 | -.1367 | .2188 | |
black | latino | .07630 | .07768 | .915 | -.1631 | .3158 |
asian | -.13473 | .08634 | .656 | -.4009 | .1314 | |
white | -.21610 | .07664 | .094 | -.4523 | .0201 | |
other | -.09366 | .08162 | .858 | -.3452 | .1579 | |
white | latino | .29241* | .03344 | .000 | .1893 | .3955 |
asian | .08137 | .05038 | .625 | -.0739 | .2367 | |
black | .21610 | .07664 | .094 | -.0201 | .4523 | |
other | .12244 | .04178 | .073 | -.0063 | .2512 | |
other | latino | .16997* | .04366 | .004 | .0354 | .3045 |
asian | -.04107 | .05767 | .973 | -.2188 | .1367 | |
black | .09366 | .08162 | .858 | -.1579 | .3452 | |
white | -.12244 | .04178 | .073 | -.2512 | .0063 | |
*. The mean difference is significant at the 0.05 level. | ||||||
Figure 6-6. SPSS Outputs of One-way ANOVA
Figure 6-6 presents SPSS outputs of the One-way ANOVA that examines the school support levels (interval measure) among five race/ethnic groups (nominal measure). The first table “Descriptive” presents mean and standard deviation scores and the number of cases included in ANOVA by five racial/ethnic groups. This table indicates that White youth perceive the highest level of school support, followed by Asian, Other, Black, and Latino youth. The second table of “Test of Homogeneity of Variances” presents whether the variances among five racial groups are equal or not. Since “Sig.” value is 0.000, which is smaller than 0.05, the result indicates that the equal variance of ANOVA assumption is violated.
The third table of “ANOVA” shows whether the differences in school support levels among the five groups are statistically significant or not. We find in the first table that the differences are statistically significant. The “F” value of 19.734 in the second last column and “Sig.” of 0.000 in the last column indicate that the differences in school support levels perceived by the five racial groups are statistically significant. However, we don’t know yet which groups are significantly different because there are five racial groups. The Independent Sample t-test compares two groups, so it is easy to compare which group is higher than the other. ANOVA compares 3 or more groups, so it requires a paired comparison among five groups such as the mean score of Whites’ school support compares to Asians', Blacks', Latinos', and Others’, the mean scores of Asians’ school support compares to Blacks’, Latinos’, Others’, and Whites’, as a total of 20 paired comparison. The fourth table “Post Hoc Multiple Comparison” presents this paired comparison. In this table, we review the fourth column that displays the significance level of a paired comparison. In this example, Asians, Others, and Whites’ school support levels are significantly higher than Latinos.
Based on this example, the following is the write-up to report ANOVA results in Tables 6-9 and 6-10.
Table 6-9. Sample Write-up of One-Way Analysis of Variance Results |
One-way ANOVA was conducted to compare the mean of school support level (scale variable) by race (nominal variable). The mean levels of school support for White adolescents were the highest (m=3.57, sd=0.66, n=1127), followed by Asians (m=3.48, sd=0.73, n=262), African Americans (m=3.35, sd=0.76, n=100), and Others (m=3.44, sd=0.71, n=426). Results showed that there was a significant difference in school support levels across the five groups of race/ethnicity (F = 19.73, df= 2754[7], p< 0.001). Post Hoc test revealed that Latino adolescents were significantly lower in school support levels, compared to Asians (p <0.02), Whites (p <0.001), and Other ethnic groups (p=0.04). |
Table 6-10 Table Template of ANOVA Result | ||||||
Table # School Support by 5 Racial Groups (One-way ANOVA) | ||||||
| N | Mean | SD | F | df | p |
Asian | 262 | 3.48 | 0.726 | 19.73 | 2754 | .000 |
Black | 100 | 3.35 | 0.757 | |||
Latino | 844 | 3.27 | 0.836 | |||
White | 1127 | 3.57 | 0.657 | |||
Other | 426 | 3.44 | 0.712 | |||
Chi-Square Test
Chi-Square Test examines an association between the two nominal variables of IV and DV. Table 6-11 and Figure 6-7 present steps for the Chi-Square test. Figure 6-8 presents an example of SPSS outputs. This example is to examine an association between gender and obesity in terms of whether gender is associated with obesity. In this example, IV is gender and DV is obesity.

Figure 6-7. Steps for Chi-Square Test
Table 6-11. Steps for One-Way Analysis of Variance |
1. ‘Analyze’ on the top menu in Data View or in Variable View 2. Choose ‘Descriptive Statistics’ on the second option from the top 3. Choose ‘Crosstab’ on the middle 4. Choose a nominal variable from the variable list on the left side 5. Click the arrow or double-click the variable to move the nominal variable to the right side of either ‘row’ or ‘column’ on the right → DV to column and IV to row 6. Click “Statistics” and check “Chi-square” from the pop-up box 7. Click “Continue” 8. Click “Cell” and check “Column” under “Percentages” in the middle 9. Click “Continue” 10. Click ‘OK’ |
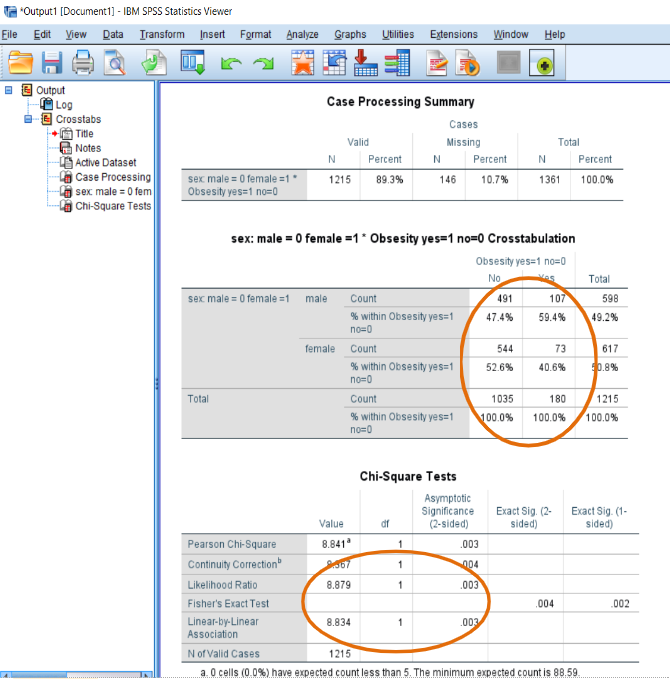
Figure 6-8. SPSS Output of Chi-Square Test
In Figure 6-8, the first table shows the number of cases included in the Chi-Square test. The second table presents two by two cross-tabulation since gender and obesity have two groups. In this table, the column “No, not obese” shows that females are 52.6% (n=544) and males are 47.4% (n=491) while the column “Yes, obese” shows that females are 40.6% (n=76) and males are 59.4% (n=107). This result indicates that more females are not obese in the first column and more males are obese in the second column. This association is statistically significant presented in the third table with the first line of Pearson Chi-Square value =8.841, df=1, and “Asymptotic Significance” =0.003, which is smaller than p=0.05. An example of a write-up for the Chi-Square test results is the following.
Tables 6-12 and 6-13 display how to present the Chi-Square test results in the Results section.
Table 6-12. Sample Write-up of One-Way Analysis of Variance Results |
Chi-square test was conducted to examine whether there is an association between gender and adolescents’ perception of obesity. The results show that 59.4% (n=107) of males reported being obese while 40.6% (n=73) of females reported being obese. The Chi-Square test shows that there was a significant association between gender and obesity (χ2 = 8.84, df= 1, p = 0.003). This finding indicates that males perceived them as obese, compared to females. |
Table 6-13. Table Template of Chi-Square Test Results | ||
Table # Chi-Square Test between Gender and Obesity | ||
Obesity | No | Yes |
N (%) | N (%) | |
Gender Females | 544 (52.6%) | 73 (40.6%) |
Males | 491 (47.4%) | 107 (59.4%) |
χ2 =8.841** df = 1 p = 0.003 | ||
[1] Probability theory is to check a possibility that results with the sample used in research differ from the results with the population.
[2] Statistical significance is determined by this probability, which is generated with p-value. In general, p-value is smaller than 0.05 indicating a statistical significance. The p-value of 0.677 is greater than 0.05, indicating statistical insignificance of the relationship.
[3] Interpretation of correlation strength levels: 0 to ±.19 (no to little); ±.20 to ±.39 (low); ±.40 to ±.69 (moderate); ±.70 to ±.89 (strong); and ≥ ±.90 (very strong).
[4] Negative relationship indicates two variables moving in different directions as one variable increases then the other variable decreases (e.g., as physical health increases, depression decreases). A positive relationship indicates two variables moving in the same direction (e.g., as the work years increase, income increases).
[5] Table number should be in numerical order. In general, sample characteristics with univariate analysis is presented in Table 1, so correlation is presented as Table 2.
[6] In this analysis, DV is suicidal ideation for both analyses. Thus, DV doesn’t need to be indicated. But many students are confused about finding and presenting the values of correlation. So the two variables of IV and DV can be presented.
[7] df indicates degree of freedom based on the number of cases (the third line) and the number of groups (the first line). We report the value on the middle that is subtraction from the number of cases to the number of groups