Chapter 4: Understanding SPSS Data
Find the SPSS Program on Purple Desktop or a Campus Computer
SPSS (Statistical Package for the Social Sciences) is a widely used statistical software program in social sciences. SPSS is available mostly in the computer labs on campus with university credentials. If there is no icon of IBM SPSS on the computer screen, we can find it in the Search Box for Windows from the bottom of the monitor and open it by double-clicking the icon.
Open a Data File in the SPSS Program

Figure 4-1-1. Opening the SPSS program
When we double-click the IBM SPSS icon, the monitor displays the SPSS program as shown in Figure 4-1-1. When we don’t have a data file, then we either close the pop-up box to display the blank spreadsheet or click “New Dataset” in the first box on the right side (above the yellow-highlighted line). When we have a data file to open, we click the blue “Open” button at the bottom of the left side as “Open another file” that is yellow highlighted is set up as default as displayed in Table 4-1 and Figure 4-1-2. Once we click “Open”, the file explorer folder appears to find a file from the computer as displayed in Figure 4-1-2 (the bottom). We can also open a data file from the top main menu following the steps displayed in Figure 4-1-2 (top).
Table 4-1. Steps to Start and Open Data File |
1. Go and click “File” on the top menu 2. Click “Open” (the 2nd option) → Show four options (Data, Syntax, Output & Script) 3. Click “Data” (the 1st option) → Open “File Explorer” 4. Find a data file from “File Explorer” like a file we open for other programs |
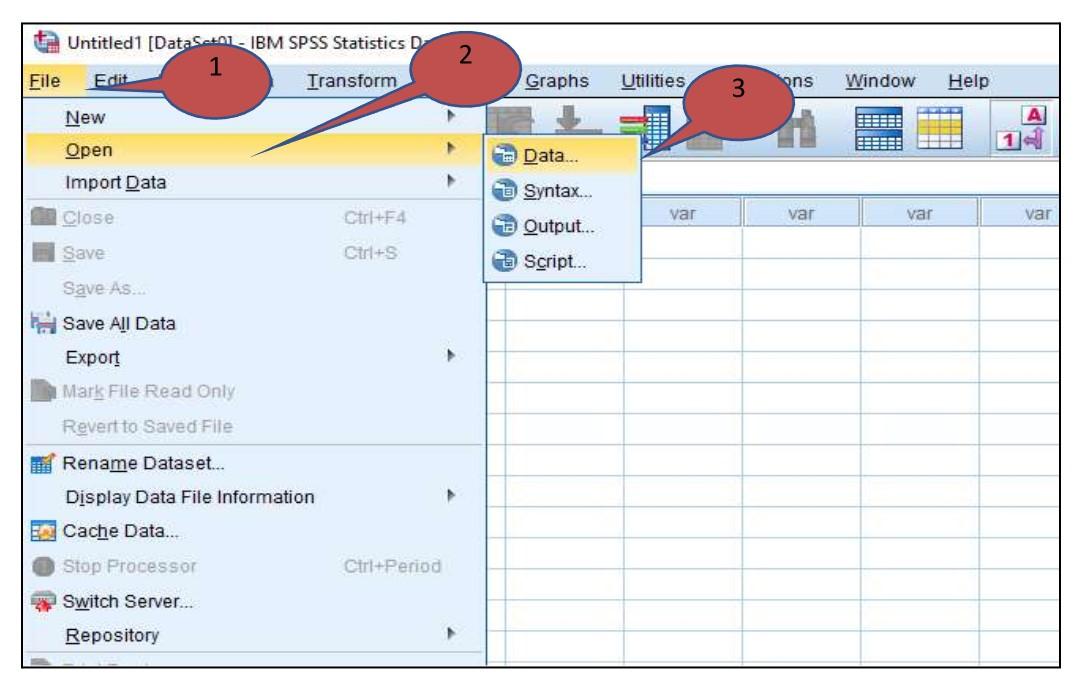

Figure 4-1-2. Open a File in the SPSS Program
As shown in Figure 4-1-2 (top), SPSS files can be saved in four different types, Data, Syntax, Output, or Script file. A data file is a file containing data while an Output file contains results from data analysis. Unique in SPSS, a syntax file is a programming language that allows us to write commands to run any types of data analysis. Generally speaking, it is not necessary to use syntax commands to run data analysis procedure since SPSS is more user-friendly for users who don’t know command language. In addition, we can create and save a syntax file that SPSS automatically creates while we are conducting data analysis. A script file is a text-based scripting language as writing tool for recording purposes such as creating a memo.
Basics of the SPSS Program: Two Screens for Displaying Data and Data Attributes
When we open the SPSS, it shows the blank spreadsheet. The bottom of the blank spreadsheet shows two squares indicating “Data View” and “Variable View.” If you see the yellow color on one of the two squares, we are seeing that view. In Figure 4-2, Data View is yellow-lighted on the left, indicating that we are with Data View. On the right, yellow-lighted on Variable View, we are seeing Variable View.
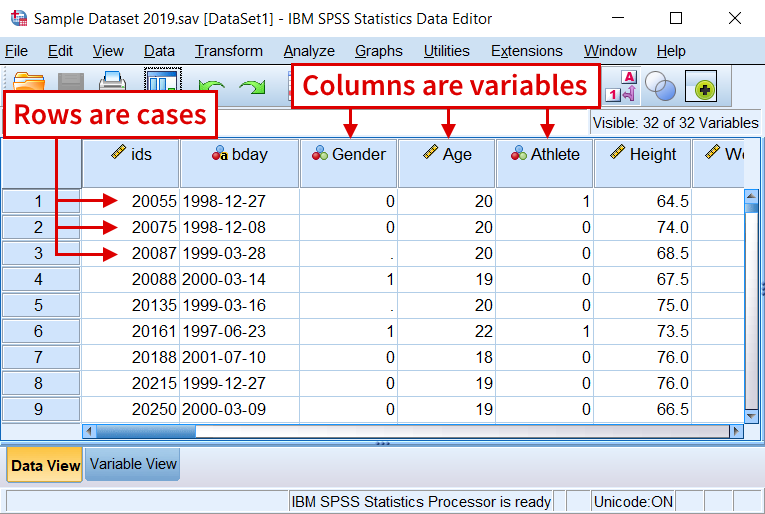
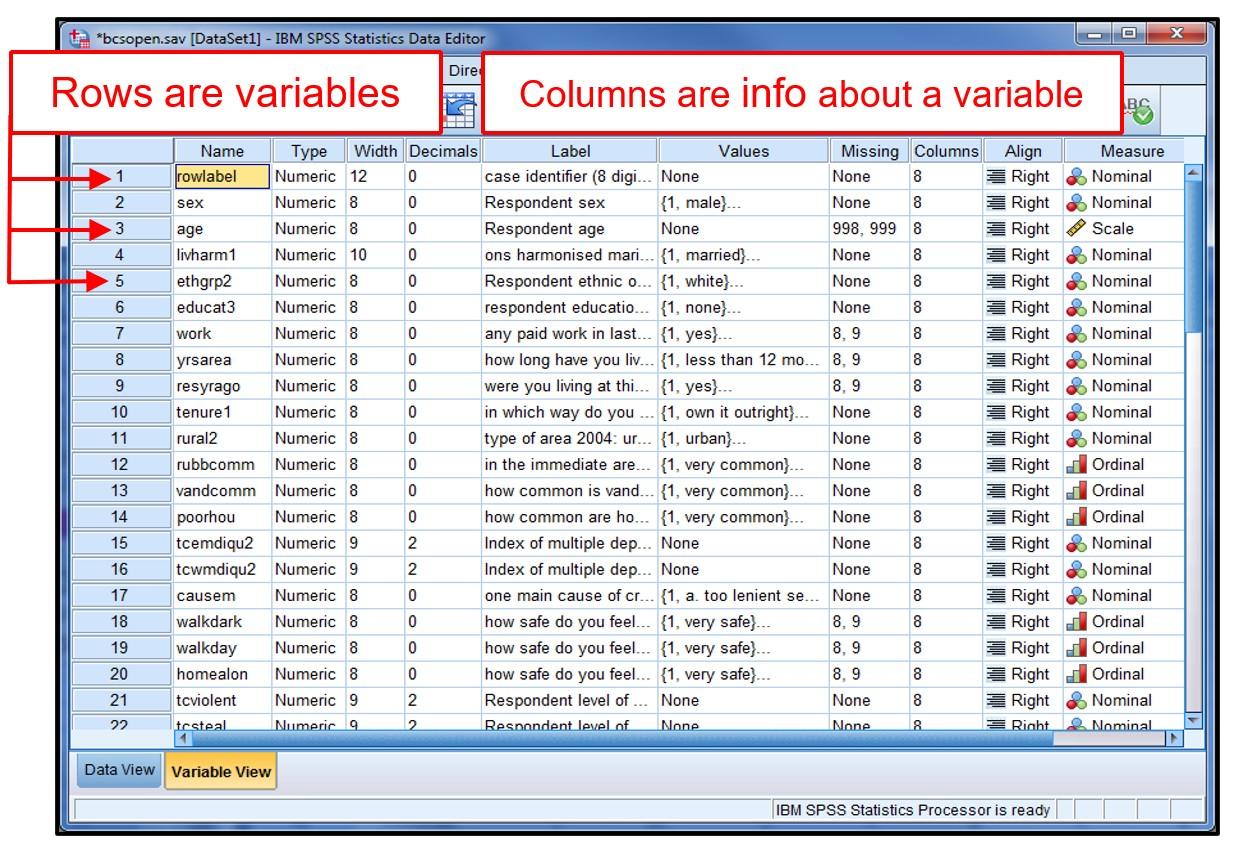
Figure 4-2 Two Screens on SPSS: Data View and Variable View
In SPSS, Data View and Variable View are working together to contain data for each corresponding variable. Data View, as shown in Figure 4-2, displays a spreadsheet of the data filled with numbers that represent the information we collect. In Data View, the column indicates different variables and the row indicates different cases/individuals/subjects.
Variable View displays all attributes and information about each of the variables, such as what the numerical data reflect. Here, each row shows each variable we collected. In case our survey contains 10 questions, we need to create at least 10 variables as one row in Variable View representing one variable and all 10 rows contain all 10 information that are collected for one case/individual. For example, if we collect data with 10 survey questions, we create 10 variables in the rows and define information of each of the variables in the columns in Variable View and 10 variable columns displayed in Data View. If we collect data from 100 survey questions, there will be 100 individual rows completed in Variable View and 100 variable columns created in Data View.

Figure 4-3 Each Column in Variable View
As displayed in Figure 4-3, there are 11 columns in the Variable View: 1) Name, 2) Type, 3) Width, 4) Decimals, 5) Label, 6) Values, 7) Missing, 8) Columns, 9) Align, 10) Measure, and 11) Role. Each column requires specific information about the corresponding variable. In the Variable View, we create variable names, and define each variable. By defining each variable in 11 columns, we provide SPSS specific information about the variable by filling out each column. So all of the 11 columns in Variable View contain information of each of the variables for each case/individual displayed as data in Data View.
The first column in the Variable View is “Name.” as shown in Figure 4-3. In this column, we can create a name of the variable that represents the information we collected. If we collect data about gender, we can name it “gender,” “sex,” and “gender_identity[1].” Demographic information is relatively easy to name. But other variables may not be easy to create variable names and remember the variable name. That is why this Variable View screen helps us keep all the information about the variables. Once we create a variable name in the Variable View, the variable names are displayed at the top of the “Data View” screen.
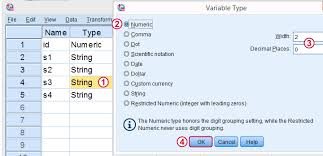
Figure 4-3-1 The Second Column of Type
The second column is “Type” as shown in Figures 4-3 and 4-3-1. This column indicates a specific type of data we are collecting such as numbers or texts. Since SPSS is for quantitative data analysis, most data are collected with numerical values. As such, the type of variable is set up with numeric as default. When we click the cell under “Type,” it shows different types of data, such as Numeric, Date, Dollar, or String as shown in Figure 4-3-1. In general, we choose “Numeric” for numbers or “String” for text data.
The third column is “Width” about the size of the column we can enter data. If we enter a long data value, then we need to set the number of digits for the variable. For example, if we have an income of 6 digits or more, we put the possible maximum column number for the income variable.
The fourth column is “Decimals ” about the number of decimal points of the data like 100.3 or 100.34. Demographic data don’t need decimal places because it is assigned a number of groups with integers. For example with a gender variable, each gender category is numerically coded with 1 for Females, 2 for Males, and 3 for Others. For other data like income or age, we may need one or two decimal points.
As displayed in Figure 4-3-2, the fifth column is “Label” about detailed information with a full or concise statement for the variable since the variable name can’t contain all the descriptions of the variable. For example, “income” can be a variable name, but it can be a monthly or annual income. We can designate a monthly or annual income in the Label column. In cases we collect data about depression with a scale that contains multiple questions like PHQ-9 (Patient Health Questionnaire) or child abuse with multiple types of physical, emotional, and sexual abuse, we need to create multiple variables in rows with similar and recognizable names. Then we can provide more information in the Label to display and keep different information for each variable created. For example, with the PHQ-9 scale, there are 9 questions to measure depression. Then we need to create 9 corresponding variables with their names. As shown in Figure 4-3-2, variable names can be created as PHQ9_1, PHQ9_2, PHQ9_3, …. PHQ9_8, and PHQ9_9. In these cases, it is hard to remember how different the nine variables are. So we can use the Label column to provide more specific information for each variable. However, it is not recommended to provide too much information in the Label column since the label information is displayed in the Output of data analysis instead of the variable name because the variable names don’t clearly show what the variables are like. It is easy for us to understand what variables we analyze in the Output with brief Labels. If the Label is too long, it is not concisely presented in the Output. Thus enough, but concise information on the Label is highly recommended.
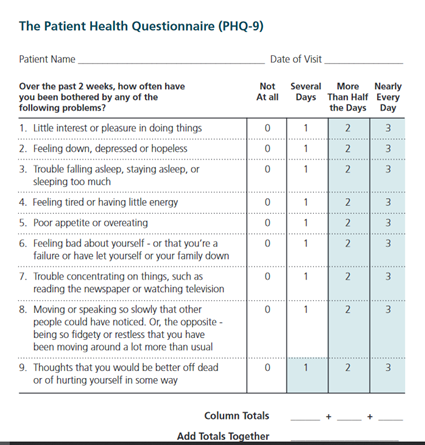

Figure 4-3-2 The Fifth Column of the Label with PHQ-9
The sixth column is “Values” as shown in Figure 4-3-3. This is about what numerical data indicate. When we see the Data View screen, data mostly display with multiple 1s, 2s, 3s, 4s, or 5s. Each 1s, 2s, 3s, 4s, and 5s in each column in the Data View is different because each column indicates different information. For example, when we have data for gender identity with 1 for females, 2 for males, and 3 for others, we enter a number of 1, 2, or 3 for each case/individual as the case’s gender identity in the Data View. Similarly, we can enter number of 1, 2, 3, 4, or 5 for each case/individual’s race/ethnicity category in the Data View as we assign the number 1 for Asian, 2 for Black, 3 for Latino, 4 for White, and 5 for Other. SPSS recognizes numbers of 1, 2, or 3 for gender identity and numbers of 1, 2, 3, 4, or 5 for race/ethnicity in the Data View. This is what we do with the “Values” column in the Variable View. When we click the cell under the Values, a box pops up to tell what each numeric value indicates for the variable.

Figure 4-3-3 The Sixth Column of Values to Add Numerical Values and Labels
As shown in Figure 4-3-3, we can type a numerical value in the first box, type a label for the numerical value in the second box, and press “enter” on the keyboard or click the Add button. We keep adding a number and label for each answer category of a variable and click “OK” once you add all numeric values and labels for the variable. This column needs to be completed when the variable is nominal (category) and ordinal (category + rank) levels of measurement. We will revisit the level of measurement in Chapter 5 when we discuss data analysis.
The seventh is “Missing,” indicating any missing information in data collection as shown in Figure 4-3-4. Research respondents sometimes skip the survey question and don’t provide their information. Then we have missing information for the variable of such cases. We can leave a blank for the cell or set up a number of the least possible value of a variable. For example, we can assign “99” or “999” for missing information about gender if the respondents don’t provide their gender because the numbers “99” or “999” is least likely to be one of the values for the gender variable. Or we can create “7 for Not sure/Don’t know” or “8 for Refused to answer” as one of the choices of the survey questions for people who don’t want to provide their information or are not sure about their gender. In many cases, we exclude those cases/individuals who mark “7 for Not sure/Don’t know” or “8 for Refused to answer” as missing information because there is no point in including this information when we analyze gender with other variables because we don’t know their gender. In these cases, we mark 7 and 8 as missing values using this column of “Missing.” As shown in Figure 4-3-4, when we click the cell under the “Missing” column, it shows a little blue square box with 3 dots. When we click it, an interface box pops up. We can pick one of the options for missing data. The second one, “Discrete missing values,” is used for separate missing values of 7 and 8 as discussed in the above example. Alternatively, we can add any missing values like “99,” “999,” or “-9.” Once entering the missing values you create, then we click “OK.”
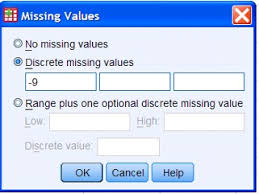
Figure 4-3-4 Entering Missing Values in the Seventh Column
The eighth column is “Columns,” about the cell size. We don’t need a big cell size for numeric data unless we have long numbers like incomes of 6 digits or more. But we need a big size of cell for text data to type all qualitative responses. When we click the cell under “Columns,” we can increase or decrease the cell size.
The ninth column is “Align” about formatting either the left or the right alignment of data display in Data View. The tenth column is “Measure” about the level of measurement of each variable as shown in Figure 4-3-5. We can indicate a measurement level of each variable in this cell. In the research methods class, we learn four levels of measurement, nominal, ordinal, interval, and ratio levels. In SPSS, only three levels of measurement can be indicated with nominal, ordinal, or scale. Scale level measures include both Interval and Ratio level measures because both levels are mathematically computable. This information is critical to understanding data analysis. So we will revisit it in a later chapter.
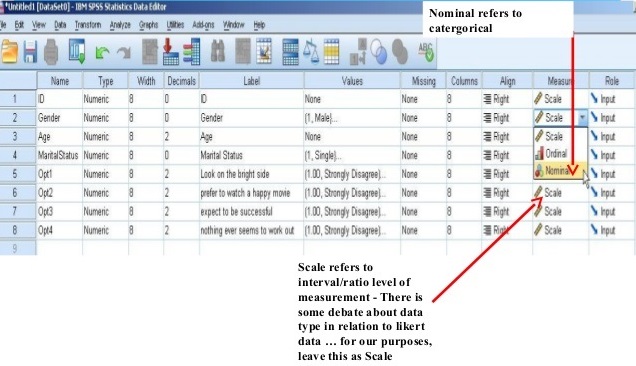
Figure 4-3-5 Measure in Tenth Column
The eleventh column is “Role,” indicating what role the variable would play in your data analysis, like independent, dependent, or both roles of the variable. It shows six options like Input, Target, Both, None, Partition, and Split. 1. “Input” means the independent variable, which is the default assignment for variables; 2. “Target” indicates the dependent variable (=outcome variable); 3. “Both” is both roles of independent and dependent variables; 4. “None” is no role assignment; 5. “Partition” means partitioning the data of the variable into a separate sample or file; and 6. “Split” indicates a role for a different SPSS program like the SPSS modeler.
Data Entering Process
Before entering numeric data, we need to complete the Variable View first by adding all information in the eleven columns for each variable in each row. Based on the information described above, we complete the Variable View with survey questionnaires. Once we complete entering all information on all columns for the first variable, we move on to the next row for the next variable and keep doing the same steps until we create and define all variables. After completing all variables in the Variable View, click the Data View tab at the bottom of the SPSS window. Then we can see the variable names on the top of the spreadsheet and begin entering numerical values or qualitative text for each variable for each case.
When we add or remove variables in the Variable View, we move the mouse to the left blue line showing the number of the variables and click the mouse’s right button (or right click). Then it shows an option of “insert” to add or “clear” to remove the variables. To add or remove cases in the Data View, we follow the same steps in the Data View.
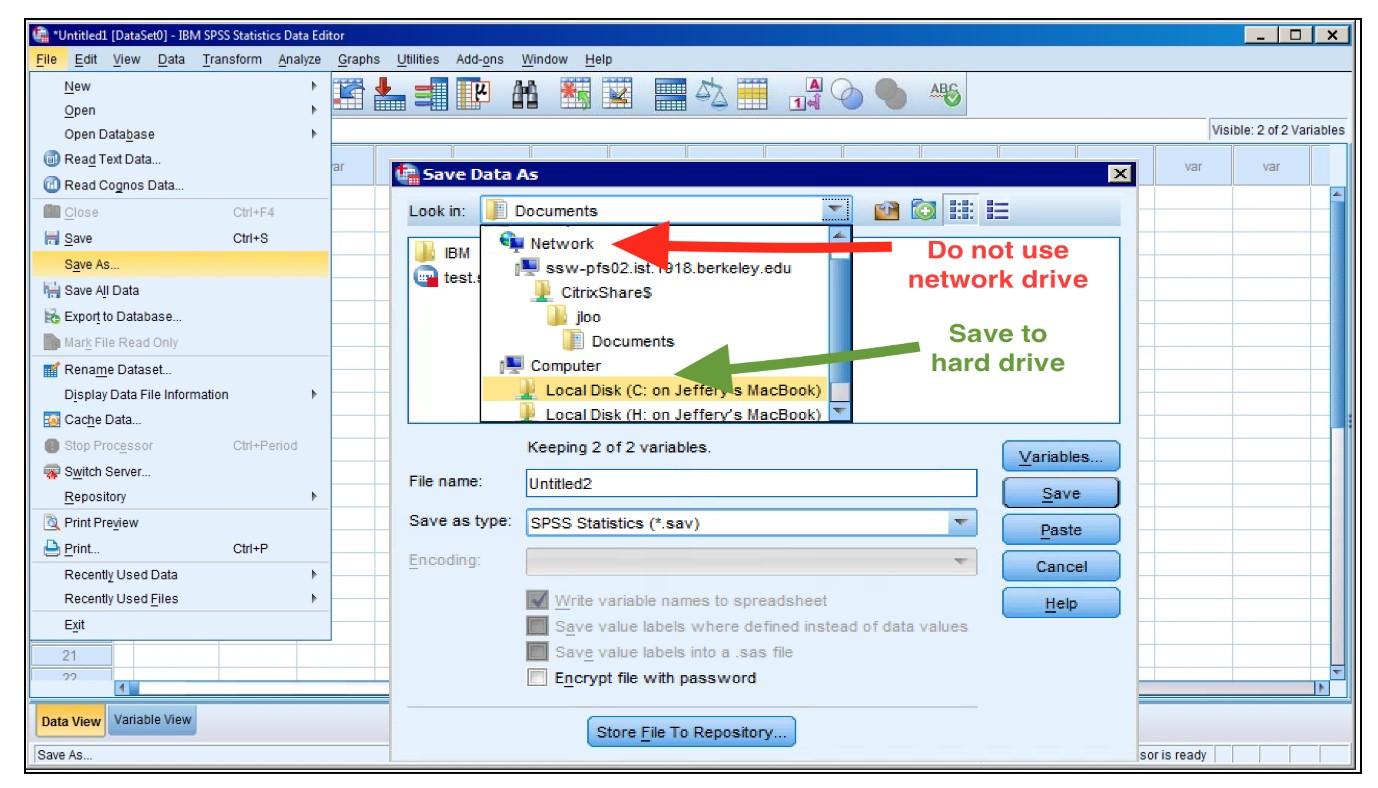
Figure 4-4 How to Save a Data File
Once finishing entering data, we save an SPSS file as shown in Figure 4-4. When we go to the top menu and choose “File,” it displays two options to save a file: “Save” or “Save As.” It is better to always save the file with “Save As” either in the Data View or Variable View, as often as possible. “Save” overwrites an old data file leading to the loss of the old data file. Many times this leads to repeating the old work once we make a mistake and can’t go back to the old file automatically. “Save As” creates a new data file and keeps the old file. So it is easy to abandon the new work and open the old file when we find a mistake in a new file.
Exercise 1. Data Entering with a Survey Question
Some useful tips for SPSS editing
- To delete an individual variable in the Variable View or a case/cases in the Data View, click the blue column on the left side displaying row numbers. Then it selects the entire line of the row. We can delete the rows by clicking the right side of the mouse and selecting “Clear” to erase the variable or cases. Or go to “Edit” on the top menu and select “Clear.”
- To copy and paste some information, click the cell to copy and click the right side of the mouse and select “Copy,” and move the mouse to the location to paste the information and select “Paste” from the right side of the mouse. Or we can use this step with the same functions of MS Word using “Ctrl C” and then “Ctrl V.”
- To select multiple variables in the Variable View or multiple cases in the Data View, locate the mouse where to select and drag down or up to select multiple rows. Once selecting multiple rows, we can copy or delete them.
[1] SPSS doesn’t allow space within the letters of the variable names. We put underscore between the multiple words of the variable name such as “Marital_Status”or “Family_Income.”